本文学习风格转换(style transfer)祖师爷Gatys的论文"Image Style Transfer Using Convolutional Neural Network"和"A Neural Algorithm of Artistic Style"。
Abstract
之前的工作无法明确地表示语义信息,因此无法将图片内容和风格区分开来。我们使用为目标检测训练出的CNN特征表示来明确地表示高层图片信息。
Deep image representations
使用归一化19层VGG网络提供的特征空间。不用任何全连接层,用average pooling比max pooling效果好。
Content representation
内容loss在内容图和生成图之间计算: $$ L_{content}(\overrightarrow p, \overrightarrow x, l) = \frac {1}{2} \sum (F ^l _{ij} - P ^l _{ij} ) ^2 $$
Style representation
分别计算生成图和风格图中间层的Gram矩阵$ A ^l _{ij} $和$ G ^l _{ij} $作为它们的风格表示,其中$ G ^l _{ij} $的计算方法如下: $$ G ^l _{ij} = \sum _k F ^l _{ ik } F ^l _{ jk } $$ 那么生成图和风格图之间的总风格loss为: $$ E_l = \frac {1} { 4 N_l^2 M_l^2 } \sum _{ i,j } ( G ^l _{ij} - A ^l _{ij} ) ^2 $$
$$ L _{style} ( \overrightarrow a, \overrightarrow x ) = \sum _{ l=0 } ^L w_l E_l $$
Style transfer
我们需要最小化如下loss:
$$ L _{total} ( \overrightarrow p , \overrightarrow a , \overrightarrow x ) = \alpha L _{content} ( \overrightarrow p, \overrightarrow x ) + \beta L _{style} ( \overrightarrow a, \overrightarrow x ) $$
其算法结构如下:
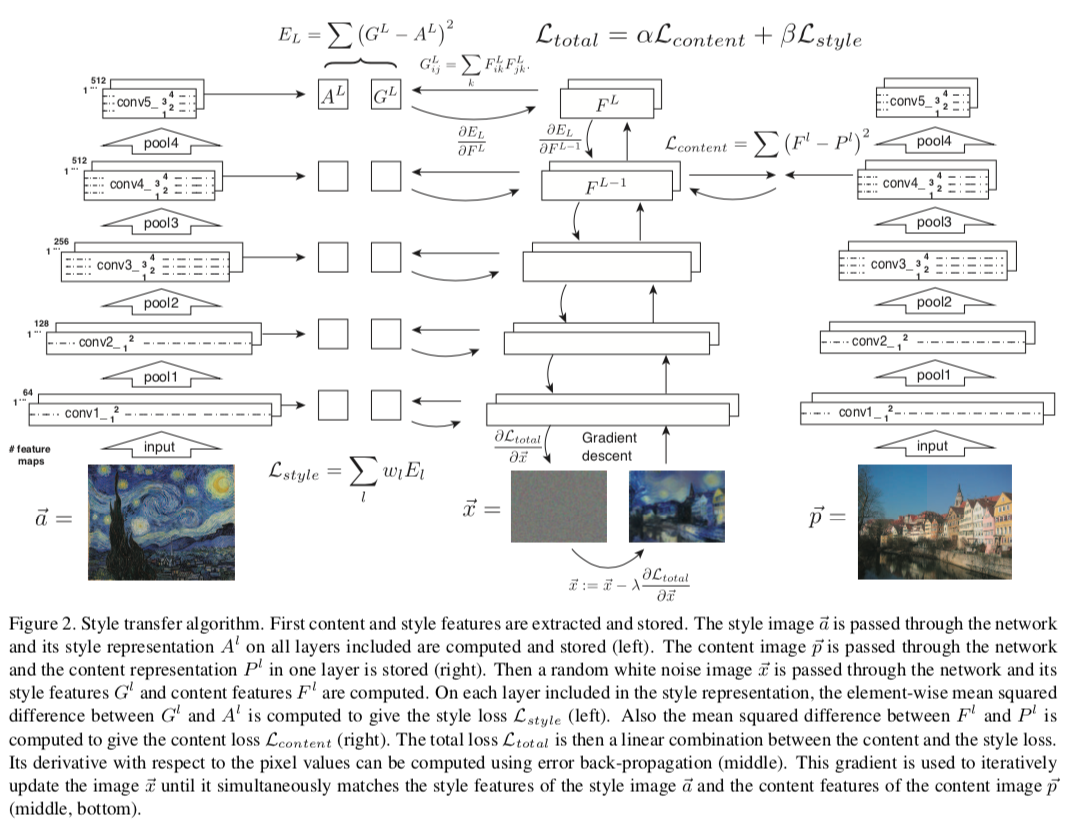
- 在图片合成中,L-BFGS优化效果最好
- 为了在可比较的范围内提取图片信息,在特征表示计算之前,经常会把风格图片的size缩放到和内容图片一样
- 没有用image priors进行规范化
- image priors:图片中相邻的像素可能会比较相似,所以部分损失函数中会加上image priors这一项:如相邻的像素点差值的平方和
Results
实验结果如下所示,其中内容用了conv4_2层,风格用了conv1_1, conv2_1, conv3_1, conv4_1, conv5_1层

Initialisation of gradient descent
白噪声图、内容图、风格图初始化的结果相差不是很大
Discussion
- 训练速度与图片分辨率线性相关
- 有时会受限于低阶噪声,艺术风格转化是问题不是很大,但当内容图和风格图都是照片时会是一个比较严重的问题
- 将图片内容和风格分开表示并不是一个定义的很好的问题
参考
Image Style Transfer Using Convolutional Neural Network
A Neural Algorithm of Artistic Style

